
前边的著述中深爱激情网,作家共享了一种偏重反念念的AI Agent缱绻形态,即Basic Reflection。但濒临复杂度很高的家具时,还有另一种框架不错惩办。便是本文先容的Reflexion缱绻形态。

在著述《AI大模子实战篇:Basic Reflection,AI Agent的支配互搏之术》中,风叔结合旨趣和具体源代码,正式先容了第一种偏重反念念的AI Agent缱绻形态,即Basic Reflection。Basic Reflection 的念念路额外朴素,便是通过支配互搏让两个Agent互相进化,收尾资本也较低。
可是在实践应用中,Basic Reflection的Generator生成的效果可能会过于发散,和咱们条目的效果相去甚远。同期,迎濒临一些复杂度很高的问题时,Basic Reflection框架也难以惩办。有两种要领来优化Basic Reflection,一种是边推理边履行的Self Discover形态,一种是加多了强化学习的Reflexion形态。
上篇著述《AI大模子实战篇:Self Discover框架,万万想不到Agent还能这么推理》,风叔沿着“边推理边履行”的优化道路先容了Self Discover。这篇著述中,风叔沿着“强化学习”这条优化道路,正式先容下Reflexion缱绻形态。

01 Reflexion的想法
Reflexion实质上是强化学习,不错结实为是Basic reflection 的升级版。Reflexion机制下,整个架构包括Responder和Revisor,和Basic Reflection机制中的Generator和Reflector有点通常。但不同之处在于, Responder自带批判式念念考的叙述,Revisor会以 Responder 中的批判式念念考手脚险峻文参考对运转回答作念修改。此外,Revisor还引入了外部数据来评估回答是否准确,这使得反念念的内容愈加具备可靠性。
下图是Reflexion的旨趣:
Responder摄取来私用户的输入,输出initial response,其中包括了Response、Critique和器具教唆(示例图中是Search)
Responder将Initial Response给到履行器具,比如搜索接口,对Initial Response进行初步检索
将初步检索的效果给到Revisor,Revisor输出修改后的Response,并给出援用开首Citations
再次给到履行器具,周而复始,直到轮回次数
Revisor将最终效果输出给用户

02 Reflexion的收尾过程
底下,风叔通过实践的源码,正式先容Basic Reflection形态的收尾要领。眷注公众号【风叔云】,回话关节词【Reflexion源码】,不错获得到Reflexion缱绻形态的齐全源代码。
第一步 构建Responder
鄙人面的例子中,咱们先构建一个Responder

为Responder细目Prompt模板,并树立一个Responder。通过Prompt,咱们告诉Responder,“你需要反念念我方生成的谜底,要最大化严谨进程,同期需要搜索查询最新的磋商信息来矫正谜底”。

第二步 构建Revisor
接下来咱们发轫构建Revisor,通过Prompt告诉Revisor
应该使用之前生成的critique为谜底添加热切信息
必须在修改后的谜底中包含援用,以确保谜底开首可考证
在谜底底部要添加参考,神态为[1] https://example.com
使用之前的品评从谜底中删除过剩的信息,并确保其不最初 250 个字。

第三步构建Tools
接下来,创建一个节点来履行器具调用。天然咱们为 LLM 赋予了不同的形态称号,但咱们但愿它们齐路由到团结个器具。
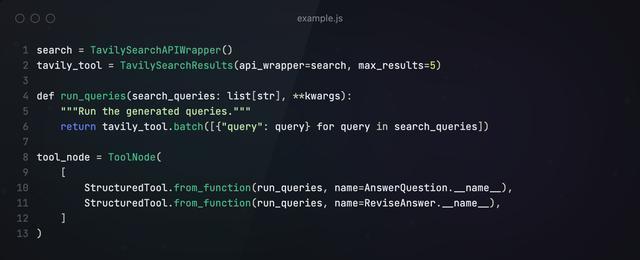
第四步构建Graph
霸凌 拳交底下,咱们构建经由图,将Responder、Revisor、器具等节点添加进来,轮回履行并输出效果。

以上内容便是Reflexion的中枢念念想,其实齐全的Reflexion框架要比上文先容的更复杂,包括Actor、Evaluator和self-Reflection三块,上文的内容只涵盖了Actor。
参与者(Actor):主要作用是把柄气象不雅测量生成文本和动作。参与者在环境中领受步履并秉承不雅察效果,从而变成轨迹。前文所先容的Reflexion Agent,其实指的便是这一块
评估者(Evaluator):主要作用是对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期牵记)手脚输入并输出奖励分数。把柄东说念主物的不同,使用不同的奖励函数(决策任务使用LLM和基于设施的启发式奖励)。
自我反念念(Self-Reflection):由大说话模子承担,大略为将来的检修提供珍惜的响应。自我反念念模子期骗奖励信号、刻下轨迹和其捏久牵记生成具体且磋议的响应,并存储在牵记组件中。Agent会期骗这些告诫(存储在弥远牵记中)来快速矫正决策。

回顾
Reflexion是咱们先容的第一个带强化学习的缱绻形态,这种形态最相宜以下情况:
智能体需要从尝试和失实中学习:自我反念念旨在通过反念念昔时的失实并将这些常识纳入将来的决策来匡助智能体进步发达。这格皮毛宜智能体需要通过反复检修来学习的任务,举例决策、推理和编程。
传统的强化学习要领失效:传统的强化学习(RL)要领经常需要无数的西席数据和微妙的模子微调。自我反念念提供了一种轻量级替代决策,不需要微调底层说话模子,从而使其在数据和经营资源方面愈加高效。
需要高超入微的响应:自我反念念期骗说话响应,这比传统强化学习中使用的标量奖励愈加高超和具体。这让智能体大略更好地了解我方的失实,并在后续的检修中作念出更有针对性的矫正。
可是,Reflexion也存在一些使用上的截至:
依赖自我评估才调:反念念依赖于智能体准确评估其发达并产生有效反念念的才调。这可能是具有挑战性的,尤其是关于复杂的任务,但跟着模子功能的禁止矫正,预测自我反念念会跟着时代的推移而变得更好。
弥远牵记截至:自我反念念使用最大容量的滑动窗口,但关于更复杂的任务,使用向量镶嵌或 SQL 数据库等高档结构可能会更成心。
代码生成截至:测试驱动开辟在指定准确的输入输出映射方面存在截至(举例,受硬件影响的非细目性生成器函数和函数输出)。
鄙人一篇著述中深爱激情网,风叔将先容当今最高大的AI Agent缱绻形态,集多种手艺的集大成者,LATS。